No ecossistema do Kubernetes, a configuração adequada dos Pods é essencial para garantir um desempenho otimizado e um uso eficiente dos recursos do cluster. Ao provisionar e gerenciar os Pods, é importante entender as diferentes classes de QoS (Quality of Service) disponíveis no Kubernetes. Essas classes - Guaranteed, Burstable e BestEffort - desempenham um papel fundamental na alocação de recursos e na priorização dos Pods em relação à disponibilidade de CPU e memória.
Conceitos básicos sobre o cluster Kubernetes
Antes de falar sobre as classes de Quality of Service (QoS) no Kubernetes, é importante entender como funcionam os recursos de CPU e memória em cada nó do cluster. Esses recursos são essenciais para o dimensionamento e a alocação adequada dos Pods, garantindo um desempenho eficiente e estável para suas cargas de trabalho.
Como funciona CPU e memória dentro do cluster do Kubernetes?
Em um cluster Kubernetes, os Nós são as máquinas físicas ou virtuais que formam o ambiente de execução dos Pods, cada Pod possui recursos de CPU e memória que são compartilhados entre todos os outros Pods no Nó. O Kubernetes gerencia e distribui esses recursos para garantir que os Pods tenham acesso adequado às quantidades necessárias para sua execução.
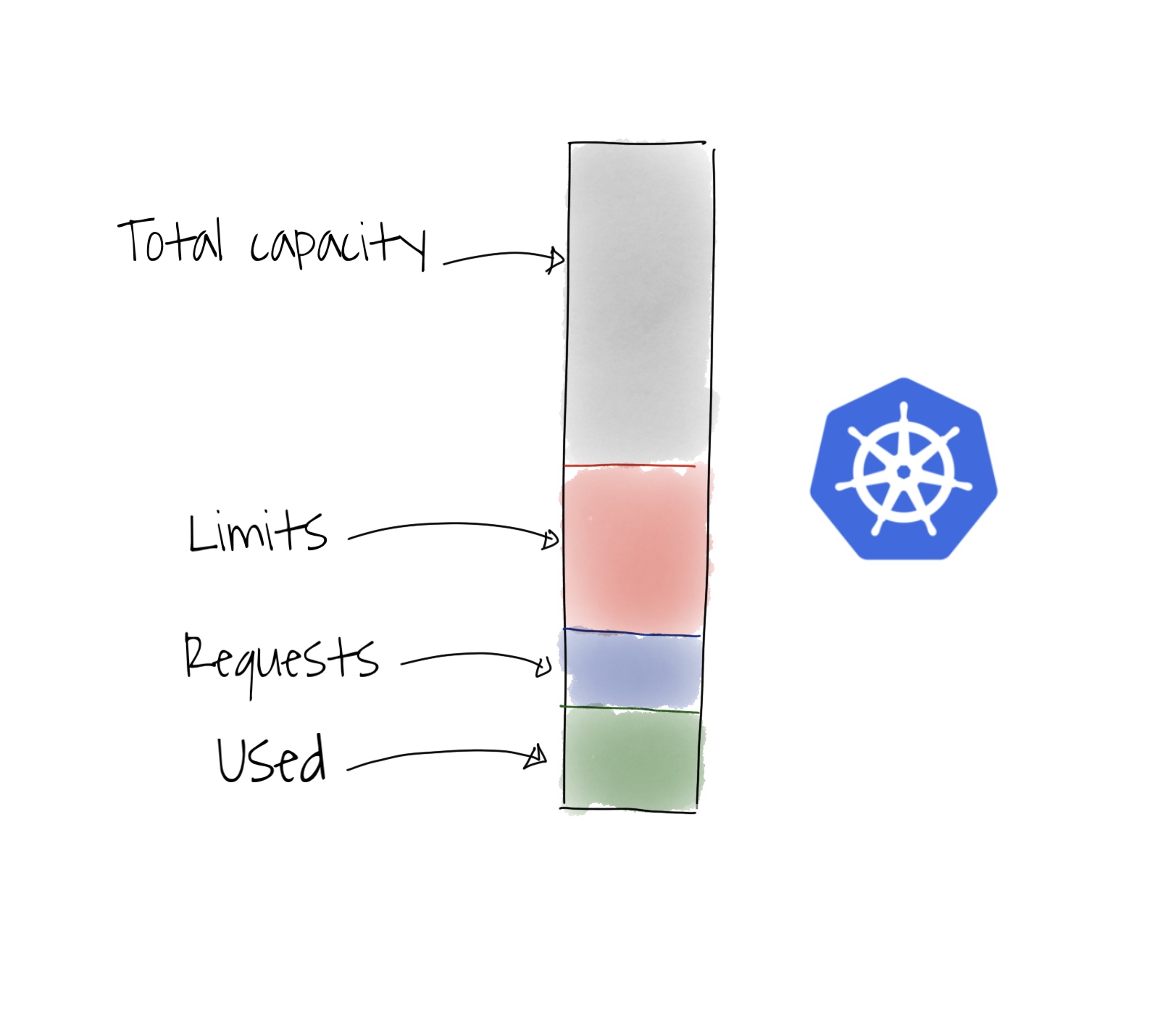
Cada nó tem uma capacidade máxima de CPU e memória, que são divididos entre os Pods e outros processos. O Kubernetes usa as configurações dos Pods de limits e requests para gerenciar a alocação desses recursos, conhecidas como QoS.
Quais as diferenças entre limits e requests?
O requests é utilizado para garantir os recursos mínimos necessários para o Pod dentro do nó. Também é utilizado pelo Kubernetes para alocar os Pods no melhor nó disponível, encaixando-os como no jogo Tetris, com base nas configurações da aplicação e disponibilidade de recursos no cluster.
Os limits funcionam como uma trava de segurança nos Pods para proteger outras aplicações, ou seja, evitam que uma única aplicação problemática utilize todos os recursos disponíveis do nó e cause problemas generalizados.
Cada um desses recursos é configurado em medidas específicas, sendo diferentes quando se trata de CPU e memória, especialmente quando se atinge os limits configurados. Falaremos um pouco mais sobre isso.
A CPU utiliza a medida de milicpu, abreviada com a letra "m". A memória utiliza a medida já conhecida de megabyte, abreviada como "Mi" ou gigabyte, abreviada como "G".
Fonte da imagem
Como funciona a medida de milicpu nos Pods?
No Kubernetes, a unidade de CPU é expressa em "núcleo de CPU" (CPU Core). Um núcleo de CPU representa uma unidade completa de processamento da CPU. Por exemplo, um nó com 4 núcleos de CPU teria uma capacidade total de 4 unidades de CPU.
A unidade de medida "m" é usada para expressar frações de uma unidade de CPU. Ela representa milicpu, ou seja, 1/1000 (um milésimo) de uma unidade de CPU. Portanto, se você especificar 100m em uma configuração de CPU, isso significa que você está solicitando ou limitando o uso de 0,1 (um décimo) de uma unidade de CPU.
Essa unidade de medida permite uma alocação mais precisa dos recursos de CPU e facilita o compartilhamento dos recursos em um nó do cluster Kubernetes. Ao usar a notação "m" para especificar as requests e limits de CPU, você pode ajustar com mais precisão a capacidade de CPU necessária para suas cargas de trabalho e garantir um uso eficiente dos recursos disponíveis.
O que acontece quando a CPU ou memória são totalmente utilizadas?
Quando a capacidade de CPU ou memória de um nó ou Pod do Kubernetes é totalmente utilizada, pode ocorrer um comportamento indesejado tanto no nó quanto nos Pods que estão sendo executados nele. É importante entender cada caso, pois são comportamentos diferentes.
Esgotamento da CPU
Quando a capacidade de CPU de um nó é excedida, o desempenho de todas as aplicações em execução no nó podem ser afetadas. O sistema operacional do nó pode se tornar lento e não responsivo, levando a uma degradação significativa no desempenho das aplicações.
O escalonador do Kubernetes tentará distribuir a capacidade de CPU disponível entre os Pods, mas se a demanda exceder a capacidade do nó, a execução dos Pods pode ficar comprometida. Em alguns casos, o nó pode se tornar inacessível ou reiniciar automaticamente para tentar resolver o problema.
Por outro lado, temos o cenário onde um Pod atinge seu limit de CPU configurado. O comportamento exato depende da configuração do Kubernetes e da política de gerenciamento de recursos adotada.
Throttling (limitação de recursos)
O Kubernetes pode aplicar throttling no consumo de CPU do Pod quando ele excede seu limite. Isso significa que o Pod terá sua utilização de CPU limitada a fim de evitar um consumo excessivo.
O Kubernetes pode reduzir a quantidade de CPU disponível para o Pod, impedindo que ele utilize mais recursos do que o limite configurado. Como resultado, o desempenho do Pod pode ser afetado, já que ele terá menos recursos de CPU disponíveis para executar suas tarefas.
Termination (encerramento)
Em alguns casos, dependendo da configuração e das políticas definidas, o Kubernetes pode optar por encerrar o Pod quando ele atinge o limite de CPU. Isso significa que o Pod será interrompido e removido do nó onde estava em execução.
O encerramento de um Pod ocorre quando há uma necessidade urgente de recursos de CPU por parte de outros Pods ou quando o limite é considerado crítico para o desempenho do cluster como um todo.
O Kubernetes pode reiniciar o Pod em outro nó ou simplesmente deixá-lo em estado de falha, dependendo das configurações e das políticas de recuperação definidas.
Em ambos os casos, a intenção é garantir que o Pod não sobrecarregue o nó ou o cluster como um todo, causando problemas maiores, permitindo uma distribuição equilibrada dos recursos de CPU disponíveis.
Esgotamento da memória
Quando a capacidade de memória de um nó é excedida, o comportamento do sistema operacional e das aplicações pode se tornar imprevisível, gerando até um problema mais critico do que o esgotamento de CPU, em alguns casos.
As aplicações em execução no nó podem ter falhas e travamentos, pois não têm memória suficiente para alocar recursos necessários, resultando em restarts forçados.
Quando um Pod atinge o seu limit de memória configurado, algumas ações podem ocorrer dependendo da política de gerenciamento de recursos configurada no Kubernetes. O comportamento exato pode variar de acordo com as configurações específicas do cluster.
OOM (Out of Memory) Killer
O OOM Killer é um mecanismo do kernel do sistema operacional que trata de situações em que a memória disponível se esgota. Quando um Pod atinge seu limite de memória configurado, o kernel do sistema operacional pode intervir e ativar o OOM Killer para liberar memória.
O OOM Killer identifica processos que estão consumindo uma quantidade excessiva de memória e os encerra para liberar recursos. Nesse caso, o Pod que excedeu o limite de memória pode ser finalizado abruptamente para liberar memória suficiente para outros processos no nó.
Falha do Pod
Em alguns casos, o Pod pode falhar imediatamente quando atinge o limite de memória configurado. Essa ação pode ser tomada para evitar que um Pod consuma todos os recursos de memória disponíveis no nó e cause impacto em outros Pods ou no próprio nó.
Quando um Pod falha, ele é interrompido e removido do nó onde estava em execução. O Kubernetes pode reiniciar o Pod em outro nó ou deixá-lo em estado de falha, dependendo das configurações e das políticas de recuperação definidas.
Imagem que ilustra o esgotamento de CPU e memória:
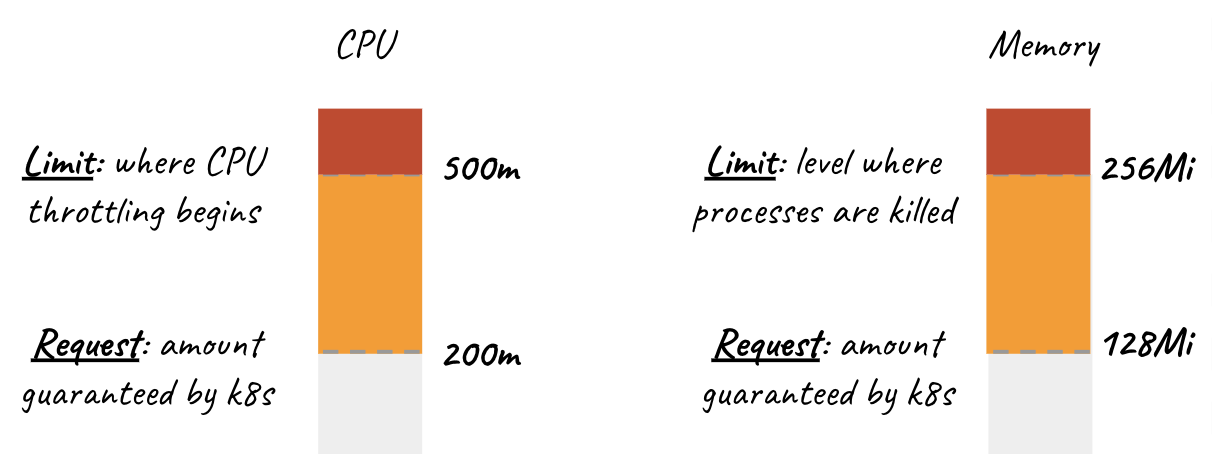
Fonte da imagem
O que é e como funciona o eviction threshold do Kubernetes?
O "eviction threshold" (limite de remoção) no Kubernetes é um mecanismo utilizado para gerenciar a alocação de recursos em um nó do cluster. Esse recurso permite ao Kubernetes monitorar e controlar o uso dos recursos, como CPU e memória, para evitar que um Pod ou um nó consuma recursos excessivamente e prejudique o desempenho geral do cluster.
O eviction threshold é definido por meio de configurações específicas em um nó do Kubernetes. Existem dois tipos principais de eviction threshold:
Eviction threshold para Pods
Essa configuração é aplicada em cada nó individualmente para controlar o consumo de recursos pelos Pods que estão sendo executados no nó. Ela é definida com base em requests e limits de recursos de CPU e memória configurados para os Pods.
Quando o uso de recursos de um Pod excede seu limite configurado, o Kubernetes pode iniciar uma ação de remoção (eviction) no Pod, liberando os recursos que ele estava consumindo em excesso. A ação de remoção pode resultar na interrupção ou reinicialização do Pod, dependendo da política de evicção configurada.
Eviction threshold para nó
Essa configuração é aplicada no nível do nó para controlar a utilização de recursos no nó como um todo. Ela é definida com base no uso global de recursos pelo nó, incluindo a soma dos recursos consumidos por todos os Pods em execução no nó.
Quando o uso de recursos em um nó atinge ou excede seu limite configurado, o Kubernetes pode iniciar uma ação de remoção nos Pods que estão consumindo mais recursos, liberando assim recursos no nó.
A ação de remoção nesse caso é geralmente realizada de forma seletiva, priorizando a remoção dos Pods com menor prioridade ou aqueles que estão consumindo mais recursos.
Essas configurações de eviction threshold são importantes para evitar situações de esgotamento de recursos em um nó ou no cluster como um todo. Elas ajudam a garantir que os recursos sejam distribuídos de maneira equilibrada e que as aplicações tenham acesso adequado aos recursos necessários para operar corretamente.
Quais outros recursos do Nó devo me preocupar?
Além da CPU e memória, existem outros recursos em um nó do Kubernetes que requerem atenção e consideração durante o planejamento e gerenciamento do cluster. Esses recursos, embora não possam ser configurados diretamente, tem um papel fundamental no desempenho e na estabilidade do ambiente Kubernetes.
Armazenamento
O armazenamento é um recurso crítico em um ambiente Kubernetes, necessário para persistência de dados e compartilhamento de arquivos entre os Pods.
Quando não há armazenamento disponível no nó, o Kubernetes não consegue provisionar novos volumes para os Pods que precisam deles. Isso pode resultar em falhas ao criar ou iniciar novos Pods que dependem de volumes de armazenamento.
Se o armazenamento estiver esgotado, as operações de gravação (write) e leitura (read) podem falhar para os Pods que dependem do armazenamento. Os aplicativos podem falhar, ficar instáveis ou interromper suas operações, dependendo da natureza de sua dependência de armazenamento.
Rede
A rede é essencial para a comunicação entre os Pods, serviços e componentes do Kubernetes. É importante considerar o desempenho, a latência e a largura de banda da rede ao planejar e dimensionar seu cluster.
Quando o recurso de rede é esgotado, a comunicação entre os Pods no mesmo nó ou em diferentes nós do cluster pode ser afetada. Os tempos de resposta podem aumentar, a latência pode ser alta e a taxa de transferência de dados pode ser reduzida.
O DNS interno do Kubernetes é responsável por resolver os nomes dos serviços em endereços IP dentro do cluster. Se o recurso de rede estiver esgotado, pode haver atrasos ou falhas na resolução de nomes, o que afeta a capacidade de localização e comunicação entre os serviços.
Não vamos nos aprofundar em cada um deles, mas é importante lembrar que eles existem e podem causar problemas quando não mensurados corretamente. Por exemplo, muitos Pods dentro de um mesmo Nó podem causar problemas de Rede neste Nó, afetando todos os Pods.
Quais outros processos existem dentro de um Nó além dos Pods de aplicações?
Dentro de um nó do Kubernetes, além dos Pods de aplicações, existem outros processos e componentes essenciais que desempenham papéis fundamentais no funcionamento e na operação do cluster. Alguns desses processos são:
Kubelet
O Kubelet é um dos componentes principais em um nó do Kubernetes. Ele é responsável por receber e executar as instruções do plano de controle do Kubernetes para gerenciar e supervisionar os Pods e os containers em um nó específico.
O Kubelet também garante que os Pods estejam em execução corretamente, monitora seu estado e reporta qualquer problema ao plano de controle.
kube-proxy
O kube-proxy é um componente responsável pelo gerenciamento do tráfego de rede dentro de um nó do Kubernetes. Ele implementa regras de balanceamento de carga e roteamento de rede para permitir a comunicação entre os serviços e os Pods no cluster.
O kube-proxy mantém as tabelas de regras de IP e de roteamento atualizadas e encaminha o tráfego de rede de forma eficiente.
Container runtime
O container runtime é o software responsável por executar os containers dentro de um nó do Kubernetes. Ele gerencia a criação, execução e destruição dos containers, bem como o isolamento entre eles.
O Kubernetes suporta vários runtimes de contêiner, como Docker, containerd, CRI-O, entre outros.
Sistema Operacional (SO)
O nó do Kubernetes executa um sistema operacional, como Linux, que possui um kernel como componente central. O kernel é responsável por fornecer uma interface entre o hardware do nó e as aplicações em execução.
O sistema operacional e o container runtime colaboram com o gerenciador de recursos do Kubernetes para alocar e gerenciar os recursos do nó, como CPU, memória e armazenamento.
Plano de controle do Kubernetes (Control Plane)
Embora não esteja diretamente no nó, o plano de controle (Control Plane) do Kubernetes é um conjunto de componentes que supervisionam e gerenciam o cluster.
Esses componentes, como o kube-apiserver, kube-controller-manager e kube-scheduler, são responsáveis por tomar decisões, gerenciar a programação dos Pods, armazenar os dados do cluster, entre outras tarefas administrativas.
O plano de controle (Control Plane) coordena as operações em todos os nós do cluster, garantindo a integridade, escalabilidade e alta disponibilidade do ambiente Kubernetes.
Resumindo os conceitos...
Tudo isso é importante conhecer antes de configurar seus Pods, pois existem vários elementos do cluster que precisam ser levados em consideração. Resumindo em tópicos o que devemos lembrar antes de falar sobre QoS:
Funcionamento diferente entre medidas de CPU e memória
Diferença entre limits e requests
Comportamento do Nó e Pods com esgotamento de recursos
Configurar o eviction threshold
Outros recursos do Nó que podem esgotar
Processos do Kubernetes disputando recursos no Nó
Diagrama de um Nó que resume visualmente os tópicos que abordamos:

Fonte da imagem: Kubernetes instance calculator
O que é Quality of Service (QoS)?
O objetivo principal do QoS no Kubernetes é garantir que os Pods tenham acesso adequado aos recursos necessários para funcionar corretamente, mantendo um equilíbrio entre a utilização eficiente dos recursos e o desempenho das cargas de trabalho.
Ao entender o QoS, os administradores e desenvolvedores podem tomar decisões sobre a alocação de recursos e a priorização de Pods, otimizando o desempenho do sistema como um todo. Com base nas características e demandas de cada aplicativo, é possível selecionar a classe de QoS mais apropriada para equilibrar a garantia de recursos, a escalabilidade e o melhor esforço.
Classe "Garantida" (Guaranteed)
A classe de QoS "Garantida" é a mais alta prioridade disponível no Kubernetes. Os Pods que pertencem a essa classe têm uma alocação estática de recursos, ou seja, uma quantidade fixa de CPU e memória é reservada exclusivamente para eles. Isso significa que esses recursos não são compartilhados com outros Pods no cluster.
Nesta classe, o Kubernetes assegura que o Pod sempre terá acesso aos recursos especificados, independentemente da carga do cluster. Essa garantia de recursos é extremamente útil para aplicativos críticos, que exigem um desempenho consistente e previsível em todos os momentos.
apiVersion: v1
kind: Pod
metadata:
name: qos-demo
namespace: qos-example
spec:
containers:
- name: qos-demo-ctr
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "200Mi"
cpu: "700m"
Exemplo retirado do site oficial do Kubernetes
Entendendo o exemplo
Podemos ver as configurações de limits e requests de CPU e memória exatamente iguais, isso caracteriza a classe QoS Garantida.
Vantagens da classe "Garantida" (Guaranteed)
Uma das principais vantagens da classe "Garantida" é a sua capacidade de fornecer isolamento e estabilidade para os Pods. Como os recursos são reservados exclusivamente para um Pod específico, não há preocupação com interferência de outros Pods em termos de disponibilidade de recursos. Isso é particularmente importante em cenários onde a previsibilidade e a consistência são fundamentais, como em aplicativos financeiros ou de processamento de transações.
Pontos de atenção da classe "Garantida" (Guaranteed)
No entanto, é importante observar que a alocação estática de recursos pode levar à subutilização. Se um Pod não utilizar completamente os recursos alocados, esses recursos não estarão disponíveis para outros Pods no cluster. Portanto, é essencial dimensionar corretamente os recursos alocados para evitar desperdício.
Em resumo, a classe "Garantida" no Kubernetes oferece a mais alta prioridade e garantia de recursos para os Pods. É indicada para aplicativos críticos que exigem desempenho consistente e previsível. No entanto, é necessário cuidado ao dimensionar os recursos para evitar subutilização e desperdício.
Classe "Escalonável" (Burstable)
A classe de QoS "Escalonável" no Kubernetes oferece um equilíbrio entre recursos garantidos e compartilhados. Os Pods que pertencem a essa classe têm uma alocação mínima de recursos garantida, mas também podem aproveitar recursos adicionais quando disponíveis no cluster.
Ao usar a classe "Escalonável", os Pods têm acesso a uma quantidade mínima de CPU e memória garantidos, assim como na classe "Garantida". Esses recursos mínimos são alocados estaticamente, assegurando que o Pod tenha pelo menos essa quantidade de recursos disponíveis, independentemente da carga do cluster.
No entanto, a diferença chave é que, se houver recursos não utilizados no cluster, os Pods escalonáveis têm permissão para aproveitá-los dinamicamente. Isso significa que, em momentos de baixa demanda, quando outros Pods não estão usando completamente seus recursos alocados, os Pods escalonáveis podem utilizar o excedente temporariamente. Isso possibilita uma melhor utilização dos recursos disponíveis no cluster, permitindo que os Pods escalonáveis atendam a picos de demanda quando necessário.
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-2
namespace: qos-example
spec:
containers:
- name: qos-demo-2-ctr
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "100Mi"
cpu: "500m"
Exemplo retirado do site oficial do Kubernetes
Entendendo o exemplo
Neste exemplo, já podemos ver as configurações de limits e requests de CPU e memória diferentes, sendo o requests com menos recursos do que o limits, isso caracteriza a classe QoS Escalonável.
Vantagens da classe "Escalonável" (Burstable)
A classe "Escalonável" é particularmente útil para cargas de trabalho que têm requisitos variáveis de recursos ao longo do tempo. Essa flexibilidade permite que os aplicativos se adaptem a picos de tráfego ou demanda sem alocar permanentemente recursos adicionais. É uma opção adequada para a maioria dos aplicativos, pois oferece um equilíbrio entre garantia de recursos mínimos e aproveitamento de recursos adicionais quando disponíveis.
Pontos de atenção da classe "Escalonável" (Burstable)
É importante considerar que, embora os Pods escalonáveis possam aproveitar recursos extras quando disponíveis, eles não têm garantia de acesso a esses recursos além da alocação mínima. Portanto, a disponibilidade de recursos adicionais pode variar dependendo da carga do cluster. Essa classe de QoS é recomendada para aplicativos que podem se beneficiar da escalabilidade, mas não exigem uma garantia estrita de recursos em todos os momentos.
Em resumo, a classe "Escalonável" no Kubernetes oferece uma alocação mínima garantida de recursos, com a capacidade de aproveitar recursos extras quando disponíveis. É adequada para cargas de trabalho com requisitos variáveis e oferece um bom equilíbrio entre garantia de recursos e escalabilidade.
Classe "Melhor Esforço" (BestEffort)
A classe de QoS "Melhor Esforço" no Kubernetes é a classe de menor prioridade e oferece pouca ou nenhuma garantia de recursos para os Pods. Nessa classe, os Pods não têm recursos alocados ou reservados exclusivamente para seu uso. Em vez disso, eles aproveitam os recursos não utilizados pelos Pods de classes superiores no cluster.
Os Pods de melhor esforço são os últimos a receber recursos no cluster. Eles utilizam livremente qualquer quantidade de CPU e memória disponíveis, desde que não estejam sendo utilizados por outros Pods de classes superiores. Essa classe de QoS é adequada para cargas de trabalho não críticas e que podem lidar bem com a falta de recursos.
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-3
namespace: qos-example
spec:
containers:
- name: qos-demo-3-ctr
image: nginx
Exemplo retirado do site oficial do Kubernetes
Entendendo o exemplo
Aqui podemos ver as configurações de limits e requests de CPU e memória inexistentes, isso caracteriza a classe QoS Melhor Esforço.
Vantagens da classe "Melhor Esforço" (BestEffort)
Os Pods de melhor esforço são ideais para aplicativos que são tolerantes a falhas e podem se adaptar às flutuações de recursos disponíveis. Eles são adequados para tarefas de processamento em lote ou serviços de menor prioridade, nos quais a disponibilidade de recursos não é essencial para o funcionamento adequado do aplicativo.
Pontos de atenção da classe "Melhor Esforço" (BestEffort)
No entanto, é importante ter em mente que os Pods de melhor esforço estão sujeitos a restrições quando a demanda por recursos é alta. Se outros Pods no cluster estiverem usando totalmente os recursos disponíveis, os Pods de melhor esforço podem enfrentar limitações e experimentar queda de desempenho.
É recomendado o uso com cautela, considerando a natureza do aplicativo e suas demandas de recursos. É importante avaliar a capacidade do aplicativo de se adaptar a flutuações na disponibilidade de recursos e garantir que a falta de recursos não afete negativamente o desempenho ou a funcionalidade essencial do aplicativo.
Em resumo, esta classe oferece pouca ou nenhuma garantia de recursos para os Pods, aproveitando os recursos não utilizados pelos Pods de classes superiores. É adequada para cargas de trabalho não críticas e tolerantes a falhas, mas é importante avaliar cuidadosamente os requisitos do aplicativo e a capacidade de lidar com a falta de recursos em momentos de alta demanda.
Posso combinar as classes QoS?
Com certeza! Inclusive, isso é uma boa prática. Cada aplicação pode ter um comportamento diferente, o que pode exigir uma configuração específica.
QoS Garantida e Escalonável
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-2
namespace: qos-example
spec:
containers:
- name: qos-demo-2-ctr
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "200Mi"
cpu: "500m"
Neste exemplo, podemos configurar a memória para trabalhar de forma garantida, ou seja, com requests e limits iguais, porém a CPU trabalhamos com a classe QoS Escalonável. Isso garante a disponibilidade de memória e a CPU pode aproveitar recursos que estejam sobrando no cluster caso precise acima do que está reservado.
Como essas classes se comportam em cenários de alto consumo?
Os Pods com a configuração de QoS Garantida têm prioridade máxima na alocação de recursos em relação aos Pods com a configuração Escalonável. Isso significa que os Pods com a configuração Garantida são garantidos a receber pelo menos os recursos definidos em suas requests, independentemente do uso de recursos pelos outros Pods no mesmo nó.
No entanto, se os Pods com a configuração Escalonável estiverem usando recursos acima das suas configurações de requests, eles podem impactar o desempenho geral do nó, incluindo o compartilhamento de recursos com os Pods de QoS Garantida. Quando há escassez de recursos no nó, o Kubernetes utiliza um mecanismo chamado fair share para distribuir os recursos disponíveis entre os Pods.
O fair share significa que, em situações de escassez, os recursos são distribuídos de forma proporcional com base nas solicitações de recursos de cada Pod. Portanto, se os Pods com a configuração Escalonável estiverem utilizando mais recursos do que suas configurações de requests, isso pode resultar em uma menor disponibilidade de recursos para os Pods com a configuração Garantida.
Essa situação pode levar a uma degradação no desempenho dos Pods com QoS Garantida, já que eles podem não receber a quantidade total de recursos que esperavam. É importante acompanhar de perto o uso de recursos pelos Pods com a configuração Escalonável e ajustar suas configurações de requests e limites adequadamente para evitar impactos negativos nos Pods de QoS Garantida. O mesmo pode acontecer com a configuração de Melhor Esforço.
Em resumo, embora os Pods com a configuração de QoS Garantida tenham prioridade na alocação de recursos, o uso excessivo de recursos pelos Pods com a configuração Escalonável ou Melhor Esforço pode afetar indiretamente os recursos disponíveis para os Pods de QoS Garantida, resultando em uma possível degradação do desempenho generalizada.
Por isso, é importante ter cuidado na configuração dos limits. Uma configuração muito "distante" entre requests e limits pode causar esse problema. Procure manter valores próximos, assim garantimos que essa "trava" de segurança evite que seu nó fique sobrecarregado.
Gerenciar cuidadosamente as configurações de recursos e monitorar o uso de recursos de todos os Pods é fundamental para manter um equilíbrio adequado e garantir o desempenho para todas as aplicações no cluster.
Certo, mas qual classe devo utilizar?
A resposta é sempre depende. Não existe certo ou errado, existe o melhor caso de uso para suas aplicações. É importante entender cada modelo de uso, suas vantagens e aplicar conforme a necessidade, levando em consideração tudo que abordamos no artigo.
Não é uma tarefa fácil, por isso é importante sempre acompanhar o consumo de todos os recursos de um cluster, pois eles podem mudar de comportamento ao longo do tempo e exigir novas configurações para manter sua disponibilidade e eficiência.
Calculando a capacidade de um Nó
Existe uma ferramenta bem interessante que ajuda a calcular a capacidade de um Nó expecifico em ambientes de Cloud.
https://learnk8s.io/kubernetes-instance-calculator
Este link também tem muito conteúdo similar ao que tratamos aqui, então além de ferramenta, fica a recomendação de leitura.
Aprofundando mais o conhecimento
Sugestões de outros sites para aprender mais sobre este assunto:
Este artigo foi elaborado com apoio do ChatGPT




